Kubernetes: Make your services faster by removing CPU limits
At Buffer, we’ve been using Kubernetes since 2016. We’ve been managing our k8s (kubernetes) cluster with kops, it has about 60 nodes (on AWS), and runs about 1500 containers. Our transition to a micro-service architecture has been full of trial and errors. Even after a few years running k8s, we are still learning its secrets. This post will talk about how something we thought was a good thing, but ended up to be not as great as we thought: CPU limits.
CPU limits and Throttling
It is s general recommendation to set CPU limits. Google, among others, highly recommends it. The danger of not setting a CPU limit is that containers running in the node could exhaust all CPU available. This can trigger a cascade of unwanted events such as having key Kubernetes processes (such as kubelet) to become unresponsive. So it is in theory a great thing to set CPU limit in order to protect your nodes.
CPU limits is the maximum CPU time a container can uses at a given period (100ms by default). The CPU usage for a container will never go above that limit you specified. Kubernetes use a mechanism called CFS Quota to throttle the container to prevent the CPU usage from going above the limit. That means CPU will be artificially restricted, making the performance of your containers lower (and slower when it comes to latency).
What can happen if we don’t set CPU limits?
We unfortunately experienced the issue. The kubelet , a process running on every node, and in charge of managing the containers (pods) in the nodes became unresponsive. The node will turn into a NotReady state, and containers (pods) that were present will be rescheduled somewhere else, and create the issue in the new nodes. Definitely not ideal isn’t it?
Discovering the throttling and latency issue
A key metric to check when you are running container is the throttling . This indicate the number of time your container has been throttled. Interestingly, we’ve discovered a lot of containers having throttling no matter if the CPU usage was near the limits or not. Here the example of one of our main API:
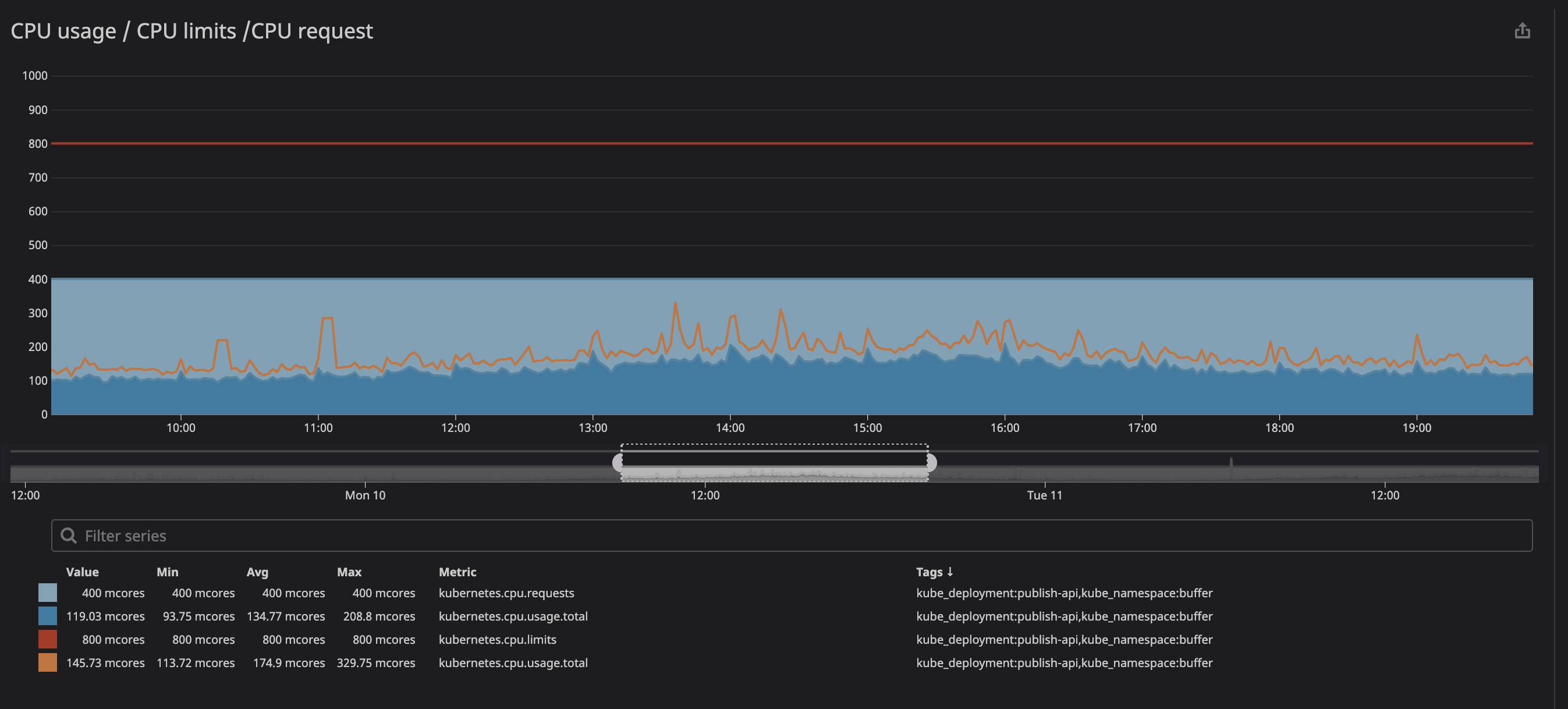
You can see in the animation that the CPU limits is set at 800m (0.8 core, 80% of a core), and the peak usage is at most 200m (20% of a core). After seeing, we might think we have plenty of CPU to let the service running before it throttle right? . Now check this one out:
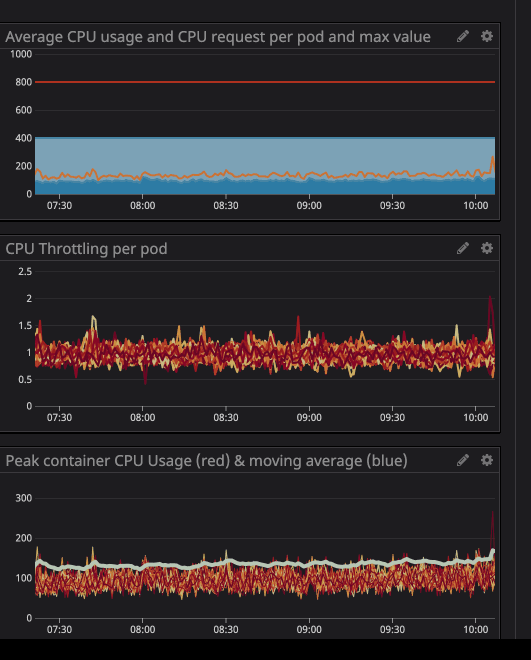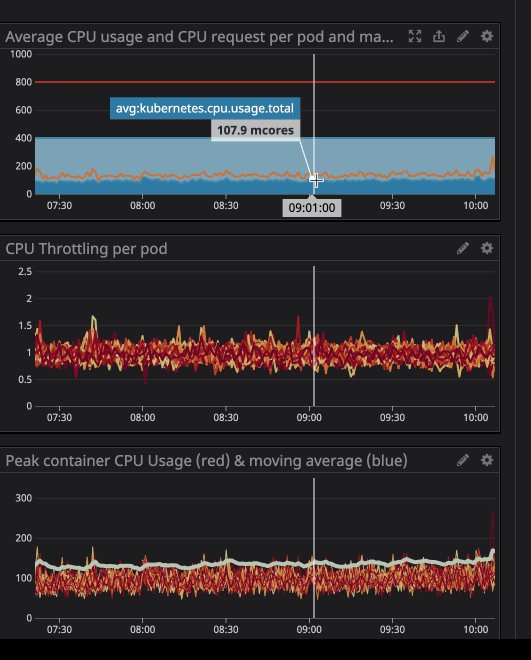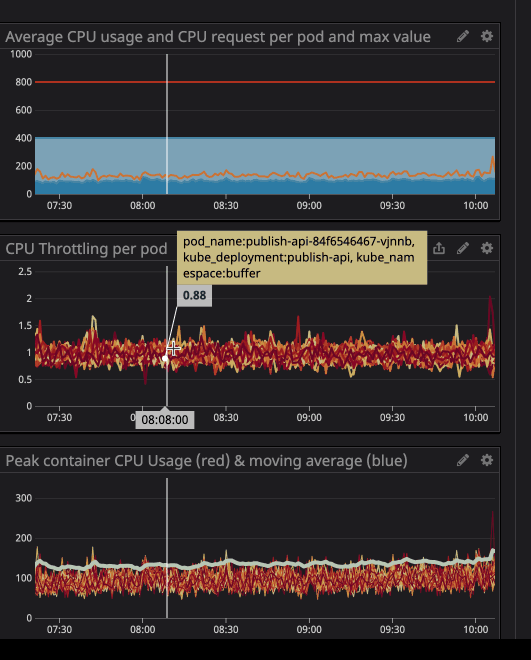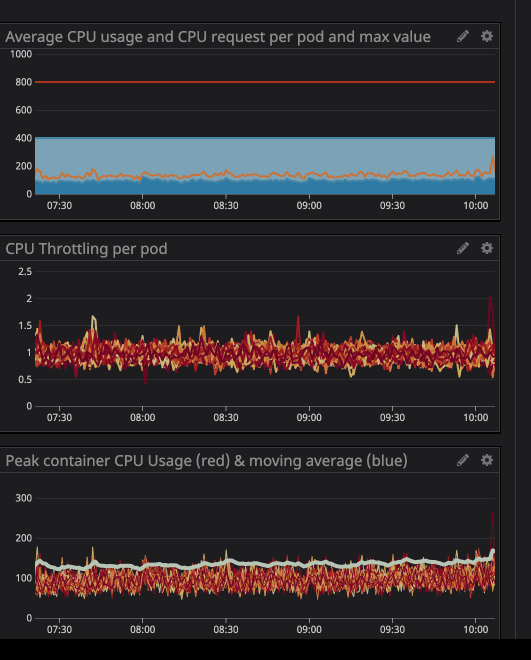
You can notice the CPU throttling occurs, even though the CPU usage is below the CPU Limits. The maximum CPU usage isn’t even near the CPU limits.
We’ve then found a few resources(github issue, Zalando talk, omio post) talking about how throttling lead to poorer performances and latency for your services.
Why do we see CPU throttling while CPU usage is low? The tldr is basically a bug in the Linux kernel throttling unecessarly containers with CPU limit. If you’re curious about the nature of it, I invite you to check Dave Chiluk’s great talk, a written version also exists with more details.
Removing CPU limit (with extra care)
After many long discussions, we’ve decided to remove the CPU limits for all services that were directly or indirectly on the critical path of our users.
This wasn’t an easy decision since we value the stability of our cluster. We’ve experimented in the past some instability in our cluster with services using too much resources and disrupting all other services present in the same node. That time was a bit different, we understood more about how our services needed to be and had a good strategy to roll this out.

How to keep your nodes safe when removing limits ?
Isolating “No CPU Limits” services:
In the past we’ve seen some nodes going to a notReady state, mainly because some services were using too much resources in a node.
We’ve decided to put those services on some specific nodes (tainted nodes), so those services will not disrupt all the “bounded” ones. We have better control and could identify easier if any issue occurs with a node. We did this by tainting some nodes and adding toleration to services that were “unbounded”. Check the documentation on how you can do that.
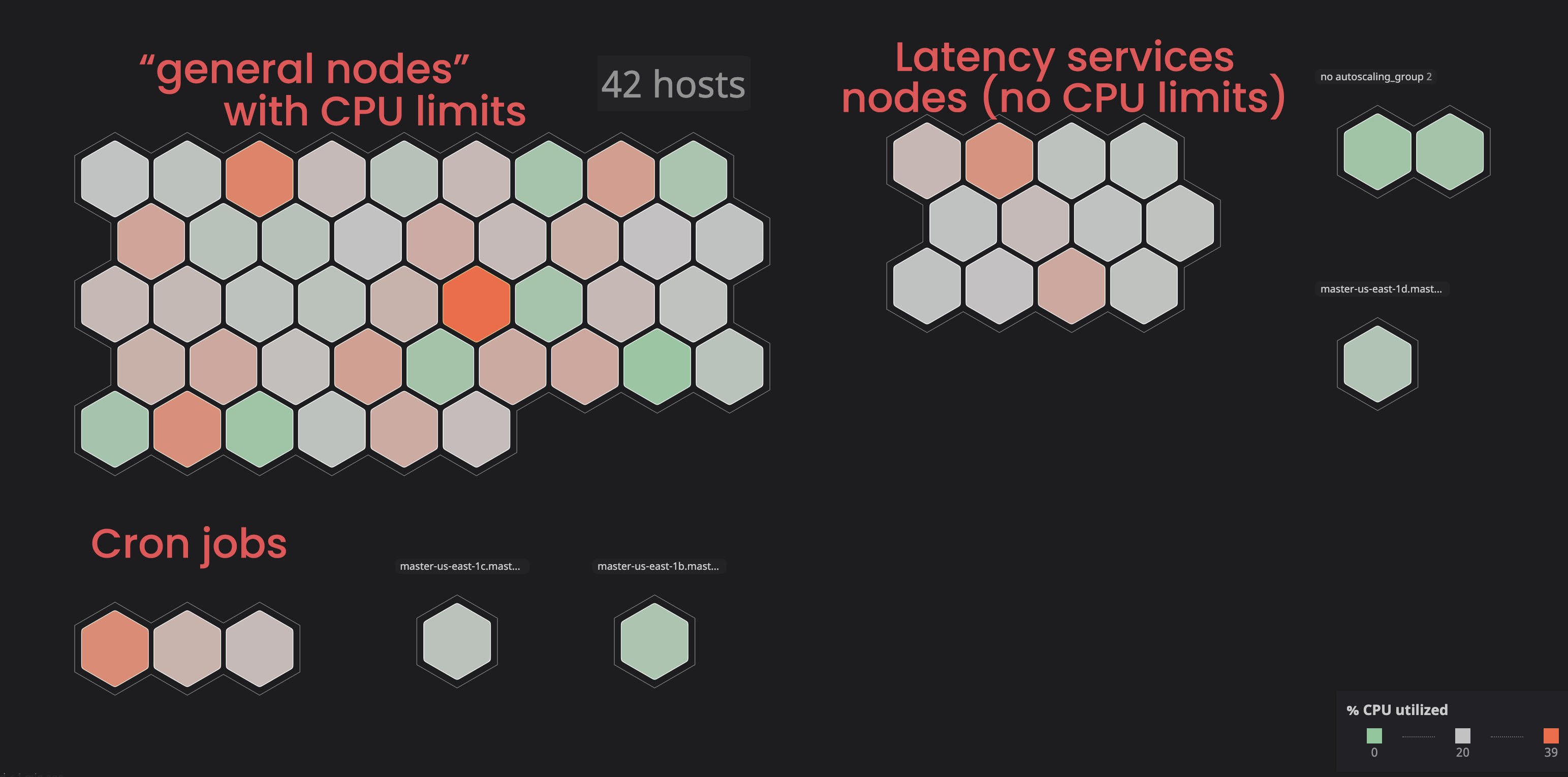
Assigning the correct CPU and memory request:
The main worry we had was service using too much resources and leading to nodes becoming unresponsive. Because we now had great observability of all services running in our cluster (with Datadog), I’ve analyzed a few months of usage of each service we wanted to “unbound”. I’ve assigned the maximum CPU usage as the CPU request with a > 20% margin. This will make sure to have allocated space in a node. If k8s won’t try to schedule any other service in that node.
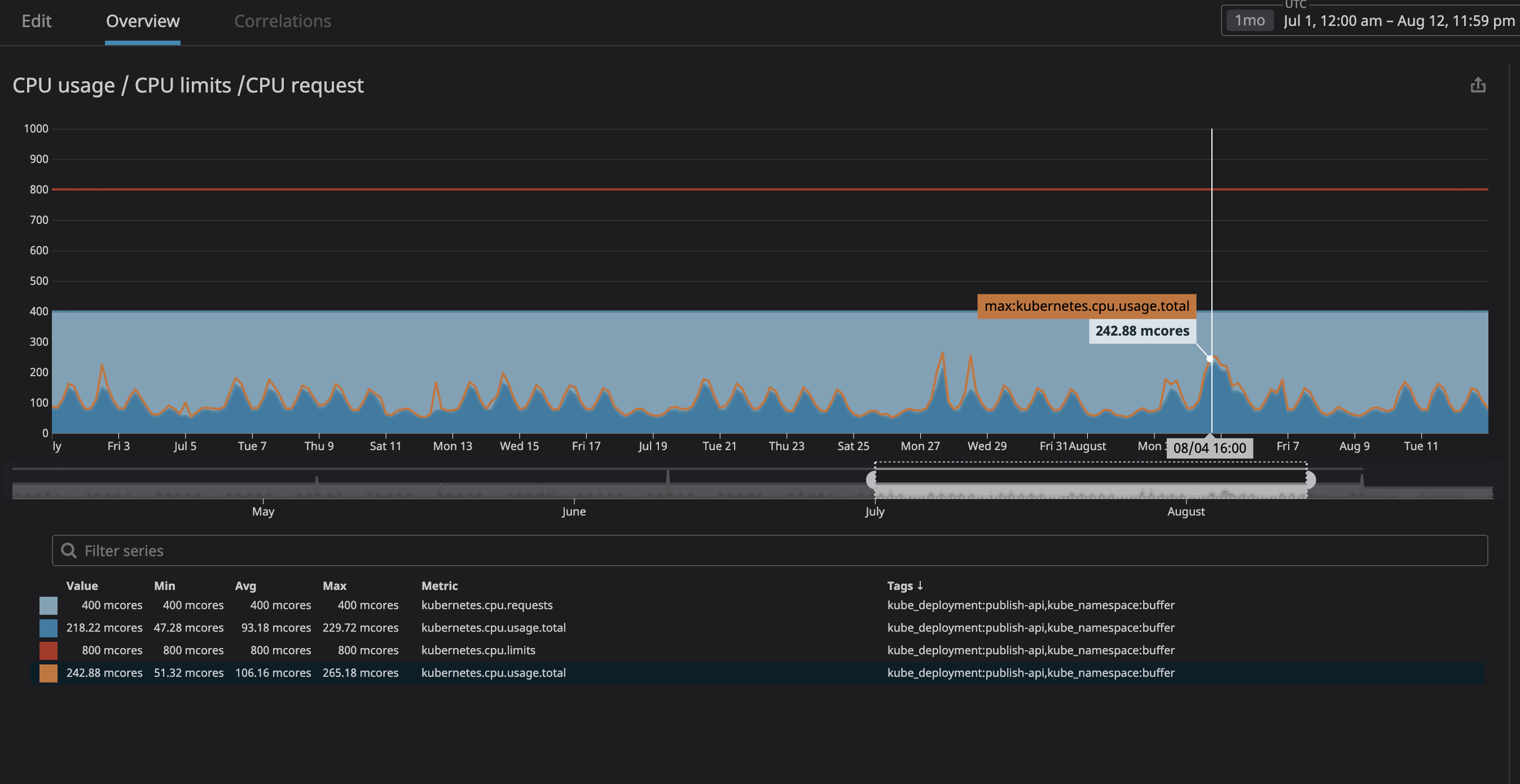
You can see in the graph that the peak CPU usage was 242m CPU core (0.242 CPU core). Simply take this number and make it a bit higher to become the CPU request. You can notice that since the service is user facing, the peak CPU usage matches peak traffic time.
Do the same with your memory usage and requests, and you will be all set! To add more safety, you can use the horizontal pod autoscaler to create new pods if the resource usage is high, so kubernetes will schedule it in nodes that have room for it. Set an alert if your cluster do not have any room, or use the node austoscaler to add it automatically.
The downsides are that we lose in “container density”, the number of containers that can run in a single node. We could also end up with a lot of “slack” during a low traffic time. You could also hit some high CPU usage, but nodes autoscaling should help you with it.
Results
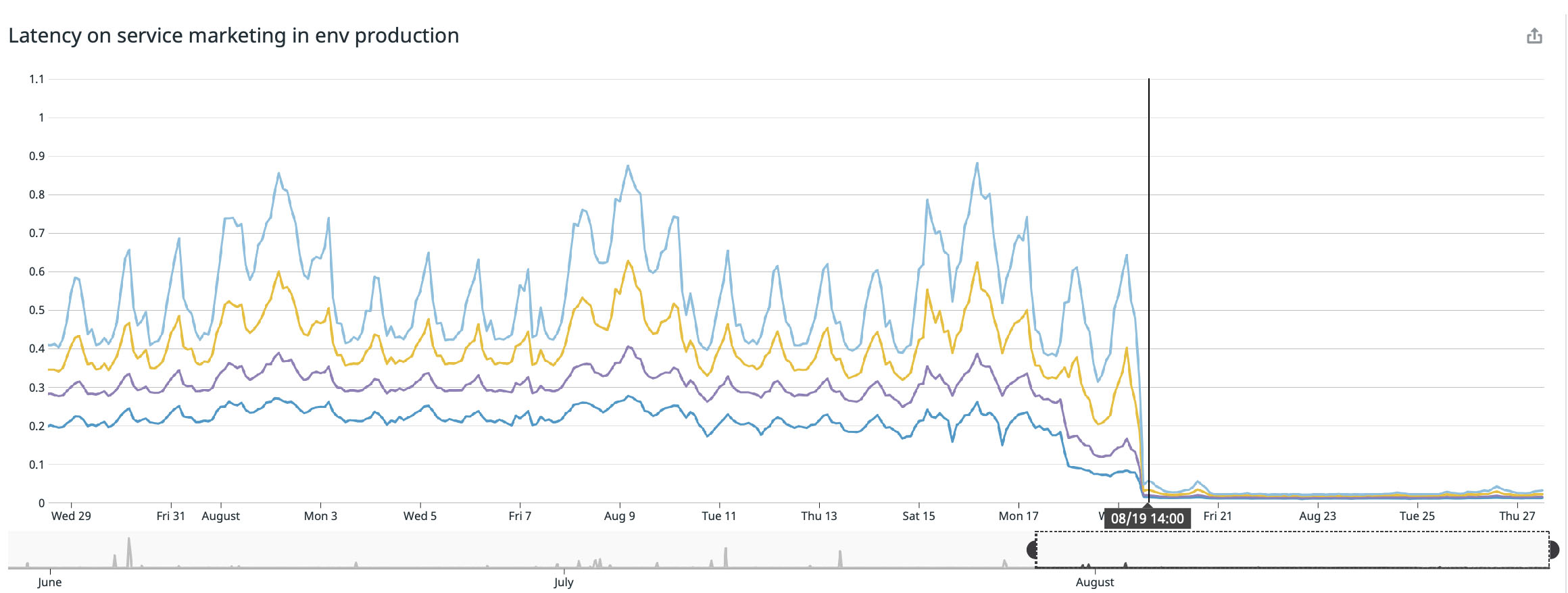
I’m happy to publish really great results after few weeks of experimentation, we’ve already seen really great latency improvements across all the services we’ve modified:
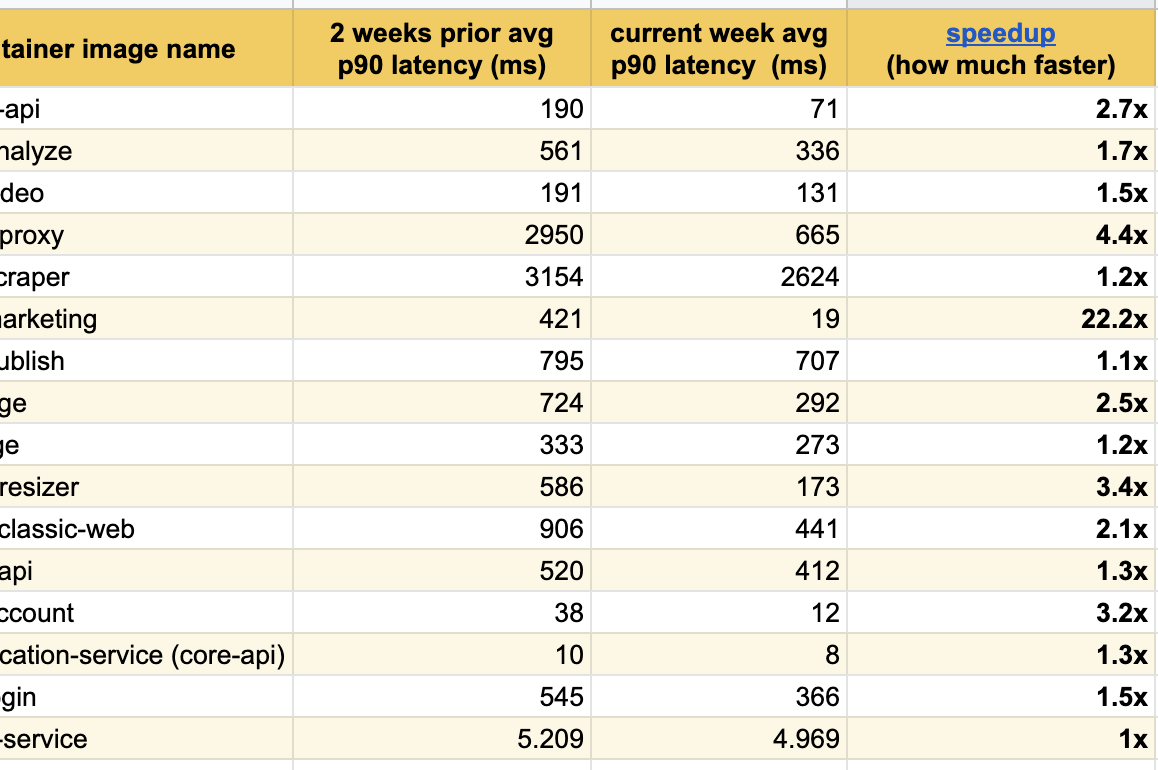
The best result happened on our main landing page (buffer.com) where we speed the service up to 22x faster!
Is the Linux kernel bug fixed?
The bug has been fixed and merged into the kernel for Linux distribution running 4.19 or higher (kudo again to Dave Chiluk for finding and fixing that).
However, as for September 2nd 2020, when reading the kubernetes issue, we can see various Linux projects that keep referencing the issue, so I guess some Linux distribution still have the bug and working into integrating the fix.
If you are below a Linux distribution that has a kernel version below 4.19, I’d recommend you to upgrade to the latest Linux distribution for your nodes, but in any case, you should try removing the CPU limits and see if you have any throttling. Here a non exhausting list of various managed Kubernetes services or Linux distribution:
- Debian: The latest version buster has the fix, it looks quite recent (august 2020). Some previous version might have get patched
- Ubuntu: The latest version Ubuntu Focal Fosa 20.04 has the fix.
- EKS has the fix since December 2019. Upgrade your AMI if you have a version below than that
- kops: Since June 2020,
kops 1.18+will start usingUbuntu 20.04as the default host image. If you’re using a lower version of kops, you’ll have to probably to wait the fix. We are currently in this situation. - GKE (Goggle Cloud) : The kernel fix was merged in January 2020. But it does looks like throttling are still hapenning
ps: Feel free to comment if you have more precise information, I’ll update the post accordingly
If the fix solved the throttling issue?
I’m unsure if totally solved the issue. I will give it a try once we hit a kernel version where the fix has been implemented and will update this post accordingly. If anyone have upgrade I’m keen to hear their results.
Takeaways
- If you run Docker containers under Linux (no matter Kubernetes/Mesos/Swarm) you might have your containers underperforming because of throttling
- Upgrade to the latest version of your distribution hoping the bug is fixed
- Removing CPU limit is a solution to solve this issue, but this is dangerous and should be made with extra-care (prefer upgrading your kernel first and monitor throttling first)
- If you remove CPU limits, carefully monitor CPU and memory usage in your nodes, and make sure your CPU requests are
- A safe way to is to use the Horizontal pod autoscaler to create new pods if the resource usage is high, so kubernetes will schedule it in nodes that have space.
👉Hacker news update: lot of insighful comments. I’ve updated the post to have better recommendations. You should prefer upgrading your kernel version over removing the CPU limits. But throttling will still be present. If your goal is low latency, remove CPU limits, but be really mindful when doing this: set the proper CPU requests, add the necessary monitoring when you do this. Read the comment written by Tim Hockin from Google (and one of Kubernetes creator)
I hope this post helps you get performance gains on the containers you are running. If so, don’t hesitate to share or comment with always some insighful comments
Special thanks to Dmitry, Noah and Andre that adviced me on this.
Next reads:
👉 Why you should have a side project
👉 How we share technical knowledge in a remote team, across timezones
Liked it?
As always, hit me up and let’s hang out. I'm now focused on antics: fun multiplayer games to play with friends - and if you're building one, we help you make your game multiplayer.
I'm also building folivue, a free portfolio tracker that brings back the classic Google Finance design.
I also gather developers in Taiwan through TaipeiDev - come join us if you're in Taipei!